Defensibility in generative AI
How to think of moat's in genAI

Hi Friends👋,
this is an essay about how I think generative AI start-ups can build defensibility. First I will look at the current tech stack, second at how defensibility can be achieved for the different layers, and last what we can expect going forward.

In my last newsletter, I argued that prompt engineering will be a crucial skill to master in order to stay relevant in the job market. This implies that there is a multitude of generative AI start-ups popping up everywhere, a few of them can be seen on this market map created by NFX. Apparently, we can also expect a few generative AI start-ups coming out of the current YC batch.
As this paradigm shift unfolds, it poses a crucial challenge to both founders and investors in the form of building companies with long-term competitiveness and sustainability. In other words, the question arises of how generative AI startups can create defensibility around their product offering.
Tech stack
In order to answer the question it is important to understand the different layers that make up the generative AI tech stack.
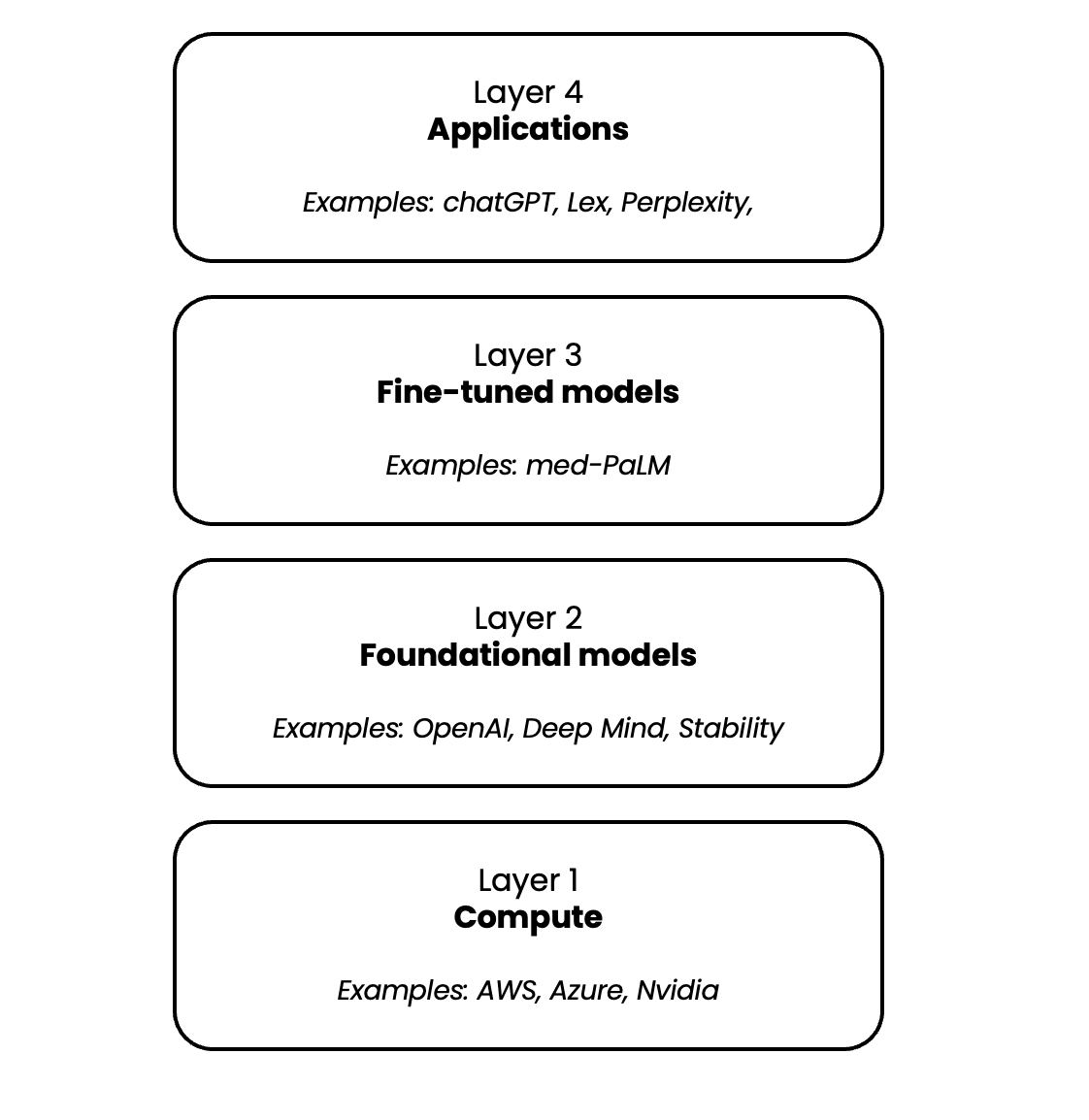
1. Compute
The compute layer, which encompasses hardware such as the A100 GPU from NVIDIA, and cloud providers such as AWS, Azure, and Google Cloud, play a critical role in the success of Generative AI. The training and running of these models are incredibly compute-intensive, making this layer a crucial component in the overall ecosystem. This has led to strategic partnerships, such as Microsoft's investment in OpenAI, which gives the latter access to Azure.
2. Foundational models
Foundational models are the backbone of Generative AI. These massive models are capable of generating a wide range of outputs, including text, code, images, videos, and more. Their creation is a daunting task that requires a significant investment in talent and expertise, as well as large amounts of training data. For instance, it costs millions of dollars to train a model like chatGPT. These models can be proprietary, such as those developed by OpenAI, or open-source, such as StableDiffusion from stability, or Open Assiant an open-source version of chatGPT.
3. Fine-tuned models
Very simplified fine-tuning is the process of using additional data to further train a foundational model on a specific use case. For example, PaLM is a large language model (LLM) able to generate text similar to GPT-3. Researchers used a variety of medical data to fine-tune PaLM to be very accurate on specific medical questions. The enhanced med-PaLM was able to answer highly specific medical questions with the same accuracy as medical professionals.
4. Applications
The last layer of the generative AI tech stack lies in the realm of user-facing applications. These applications blend together the power of foundational and fine-tuned models, wrapping them in a user-friendly interface and delivering them to the customer. Today, we see the emergence of applications such as chat-bots, chrome extensions, and image generators, just to name a few examples.
Looking at the layers making up the generative AI tech stack, we must consider the difficulties of operating within the compute layer. The market is dominated by a few large players. These factors, combined with the size advantage enjoyed by the existing players, make it challenging for new entrants to gain a foothold and establish a competitive position in this market. As such, we must look beyond compute to identify areas where defensibility can be built.
Defensibility
1. Foundational models
Hypothesis: Foundational models will be commoditized
In recent years, the development of foundational models has reached new heights, with these models being trained on vast amounts of data. For instance, GPT-3 was trained on a staggering 300 billion tokens (word fragments). Despite this, researchers at Google’s DeepMind have discovered that simply increasing the size of a model (in terms of parameters, or "neurons") is not necessarily the optimal approach for enhancing its performance. Instead, the optimal balance appears to be smaller models coupled with increased amounts of training data.
The sheer volume of data required to train these models is almost incomprehensible. In a recent article from MIT, researchers explored the possibility that we might soon run out of data to use for training, as we approach a future in which all the data on the internet has been utilized. This highlights the significance of the challenges facing researchers in the field of foundational models and the importance of finding new ways to optimize the process.
It is becoming increasingly apparent that, as time progresses, the large foundational models will be trained on an increasingly similar data set: namely, all the observable and scrapable data on the internet. This convergence of data sets will result in a similar level of performance and accuracy among the various models. Some of these models will be closed-source, while others will be open-source. The choice between using one or the other will depend on the specific use case and the particular needs of the user.
The development of foundational models is likely to be dominated by a select few big players with the capital and talent resources necessary to build these complex systems. Currently, the climate for AI research is highly favorable, as evidenced by the recent $300 million funding round for Anthropic led by Google. However, for most entrepreneurs, competition in this space is likely to be intense and difficult, as the outputs of various models converge toward commoditization.
2. Fine-tuned models
Hypothesis: Most competitive companies will use fine-tuned models
As previously noted, large, general-purpose models excel at broad, general tasks but lack expertise in specific domains. One way to address this limitation is through a process called fine-tuning, in which a general model is adapted to perform a specific function. In order to fine-tune a model, it is necessary to provide it with specific data that corresponds to the desired function.
For example, a startup looking to build a tool for generating book summaries would need to fine-tune the model on a data set of existing summaries. This allows the AI to learn the patterns and style of these summaries, and to generate more accurate output when deployed in the real world. Fine-tuning is a powerful way to extend the capabilities of general-purpose models and make them more suited to specific tasks and applications.
The process of fine-tuning AI models can occur both (1) vertically and (2) horizontally.
Vertically
Vertically fine-tuned models are designed to meet the specific needs of a particular industry or vertical. The earlier discussed fine-tuned model for the medical field, med-PaLM is a great example of this. Another area that is attracting a lot of start-up activity at present is the development of fine-tuned models for law firms.Horizontally
Horizontally fine-tuned models, on the other hand, are designed to meet the common needs of different industries within a specific business function. For example, marketing and sales tools that are capable of generating copy or cold emails are used across a wide range of consumer companies and enterprise sales teams.
For a fine-tuned model to be preferred over a general-purpose model, the improvement in the accuracy of the information generated must be significant. While a 10% to 20% increase in a model's performance in generating marketing copy may not be noticed by end-users, a 2x or 3x improvement is more likely to be noticed and appreciated. In other words, the benefits of fine-tuning must be substantial and tangible in order to drive adoption and create a competitive advantage.
Therefore, in order to build defensibility through fine-tuning, it is necessary to invest in the development of high-quality, proprietary data sets that are specifically designed to meet the needs of different tasks and applications. By doing so, it is possible to create models that outperform general-purpose models and offer real value to end-users, building a foundation for long-term success and competitiveness.
An illustrative example of the power of fine-tuning models can be seen in OpenAI's recent partnership with Shutterstock. This collaboration will allow OpenAI to train its image generation model using Shutterstock's vast library of stock photos. In turn, Shutterstock will be able to leverage the trained model to add a new, cutting-edge feature to its product offering.
An interesting infrastructure company to be built here is a platform to cost-efficiently fine-tune models and make the result accessible via an API.
3. Applications
Hypothesis: Owning the user interface will be crucial to building defensibility
Generative models, such as OpenAI's GPT-3, are most often accessed by end-users through user interfaces. One such interface is OpenAI's Playground, which allows users to easily leverage the power of GPT-3 without having to interact directly with the API.
Control over the user interface is an important factor in the defensibility of these models. By collecting data on how users interact with the model, developers can use reinforcement learning to improve the model's performance based on human feedback. This can lead to (1) lock-in and (2) data network effects.
User lock-in
Through the power of feedback loops, AI models can tap into the unique preferences and styles of individual users. This personalized approach results in increasingly accurate outputs as the model learns from each interaction. For example, consider an AI tool used for writing SEO blog posts. As a user continues to utilize the tool, the AI recognizes their writing style and adapts to generate content tailored specifically to them. This creates a strong sense of user lock-in, as switching to a different tool would require significant time and effort to recreate the personalized experience. In this way, feedback loops drive the creation of defensible AI products.
Data network effects
As more and more users interact with generative models through user interfaces, the opportunity to gather valuable usage data increases. A simple thumbs up or down on generated content can provide insight into user preferences, helping the AI to recognize patterns and continually refine its performance. When implemented correctly, this feedback loop can result in a virtuous cycle where each new user makes the overall product better for everyone else. Such network effects have the potential to create a high degree of defensibility, as the more users there are on the platform, the more valuable the data and the better the product becomes.
Ownership of the user interface and a proprietary data set for fine-tuning foundational models offer a powerful combination for creating defensibility. By continuously improving the model for individual users, a lock-in is created, leading to network effects that can only grow stronger over time. These powerful dynamic positions companies at the forefront of the AI landscape, providing a significant barrier to entry for would-be competitors.
An interesting infrastructure company to be built here is something like Shopify for generative AI. Where entrepreneurs can easily choose a model they want to use, create the reinforcement learning feedback system and deploy it via a simple
front-end or API. All without or with very limited technical expertise.
Looking ahead
Looking ahead, the market for foundational models is poised to be dominated by a select few major players, offering both closed and open-source models. These models will be used by start-ups to create horizontally or vertically integrated products.
In order for start-ups to achieve lasting success and establish a strong competitive advantage, they must not only have highly accurate fine-tuned models but also continually improve those models based on feedback from their end-users. Merely offering a 10% to 20% improvement in a model's output will not be enough to stand out from the competition and attract users, as it can easily be offset by a well-designed user interface. To truly succeed, the models must provide a significantly better experience for the end-user, one that is several times better than the next best alternative.
My hypothesis for the coming months is that a multitude of highly specialized companies focusing on niche use cases will emerge. Speed is of the essence here as the next one to two years are a land grab situation – especially for the most obvious cases. The company that can quickly bring its product to market will have the advantage of collecting the most user data and refining its models to a point of competitive superiority. Even if competitors have access to the same initial data set for model fine-tuning, it is unlikely that they will be able to close the gap.